trace コマンド
目次
概要
trace コマンドは、Python 関数の完全な呼び出しチェーンと実行時間を追跡し、ツリー構造でメソッド呼び出しの階層関係を表示します。性能ボトルネックの特定やコード実行パスの理解に役立つ強力な性能分析ツールです。
TUI での使用法
TUI モードでは 3 キーを押して Trace ビューに切り替えると、以下のインタラクティブ機能が利用できます:
- パターン入力:ターゲットプロセスからリアルタイムに取得した関数名のオートコンプリートをサポート
- パラメータ設定:深度、回数、条件式、skip-builtin を視覚的に設定可能
- 呼び出しツリーの可視化:インタラクティブなツリー構造で呼び出しチェーンを表示、展開/折りたたみが可能
- 実行時間による色分け:
- 🟢 緑:< 10ms(高速)
- 🟡 黄:10-100ms(中速)
- 🔴 赤:>= 100ms(低速)
- ショートカット操作:
- 入力モード後に Enter でトレース開始
- Enter でノードの展開/折りたたみ
cキーでトレース記録をクリア- Delete キーで選択された記録を削除
CLI との同等性:以下の例はすべて CLI コマンドでデモンストレーションしていますが、TUI は同じ機能をグラフィカルなインターフェースで提供します。
使用場面
- 性能ボトルネックの特定:実行時間データから素早く遅い呼び出しを発見
- 呼び出しリンクの分析:関数内部の呼び出し関係と実行フローを理解
- コード実行パスの追跡:さまざまな条件下でのコード実行パスを観察
- サブ関数の時間分析:各サブ関数の時間消費割合を分析
- 再帰呼び出しの診断:再帰呼び出しの深度と時間分布を追跡
コマンドフォーマット
peeka-cli attach <pid> # まずターゲットプロセスにアタッチ
peeka-cli trace <pattern> [options]
パラメータ説明
| パラメータ | 説明 | デフォルト | 例 |
|---|---|---|---|
pattern |
関数マッチングパターン | - | module.Class.method |
-d, --depth |
トレース深度(最大呼び出し階層数) | 3 |
-d 5 |
-n, --times |
観測回数(-1 は無限) | -1 |
-n 10 |
--condition |
条件式(cost 変数をサポート) |
なし | --condition "cost > 50" |
--client |
既存のクライアントセッション ID。省略時は一時クライアントを自動作成 | 自動 | --client client_123 |
--skip-builtin |
組み込み関数と標準ライブラリ関数をスキップ | true |
--skip-builtin=false |
--min-duration |
最小時間フィルタ(ミリ秒) | 0 |
--min-duration 10 |
注意:
- トレース深度は 5 層以下に抑えることを推奨。深度が大きいと性能オーバーヘッドが大幅に増加します
--skip-builtinはデフォルトで有効、出力のノイズを減らすため- 条件式の
cost変数は呼び出し全体の合計時間(ミリ秒)を表します
関数マッチングパターン (pattern)
以下のフォーマットをサポートしています:
# 1. モジュールレベルの関数
"mymodule.my_function"
# 2. クラスのメソッド
"mymodule.MyClass.my_method"
# 3. ネストされたクラスのメソッド
"mypackage.mymodule.OuterClass.InnerClass.method"
# 4. モジュールパス
"package.subpackage.module.function"
注意:インポートのルートから始まる完全なモジュールパスを使用する必要があり、現在のバージョンではワイルドカードマッチングはサポートされていません。
基本的な使い方
1. 関数呼び出しチェーンのトレース
# まずターゲットプロセスにアタッチ
peeka-cli attach 12345
# 5 回の呼び出しをトレース
peeka-cli trace "calculator.Calculator.calculate" -n 5
出力例:
{
"type": "observation",
"watch_id": "trace_abc123",
"timestamp": 1705586200.123,
"func_name": "calculator.Calculator.calculate",
"location": "AtExit",
"call_tree": [
{
"depth": 0,
"function": "calculator.Calculator.calculate",
"filename": "/app/calculator.py",
"lineno": 42,
"duration_ms": 125.3,
"children": [
{
"depth": 1,
"function": "calculator.Calculator._validate",
"filename": "/app/calculator.py",
"lineno": 18,
"duration_ms": 2.1
},
{
"depth": 1,
"function": "calculator.Calculator._compute",
"filename": "/app/calculator.py",
"lineno": 25,
"duration_ms": 98.2,
"children": [
{
"depth": 2,
"function": "math.sqrt",
"duration_ms": 95.1
}
]
},
{
"depth": 1,
"function": "calculator.Logger.info",
"filename": "/app/logger.py",
"lineno": 10,
"duration_ms": 15.7
}
]
}
],
"total_duration_ms": 125.3,
"node_count": 5
}
フィールド説明:
| フィールド | 説明 | 例値 |
|---|---|---|
watch_id |
観測 ID | "trace_abc123" |
timestamp |
タイムスタンプ | 1705586200.123 |
func_name |
ターゲット関数名 | "calculator.calculate" |
location |
観測位置 | "AtExit" |
call_tree |
呼び出しツリー(ネスト構造) | [...] |
total_duration_ms |
合計実行時間(ミリ秒) | 125.3 |
node_count |
呼び出しノードの総数 | 5 |
呼び出しツリーノードのフィールド:
| フィールド | 説明 | 例値 |
|---|---|---|
depth |
呼び出し深度(0 から開始) | 0, 1, 2 |
function |
関数の完全名 | "module.Class.method" |
filename |
ファイルパス | "/app/module.py" |
lineno |
行番号 | 42 |
duration_ms |
実行時間(ミリ秒) | 10.5 |
children |
子呼び出しリスト | [...] |
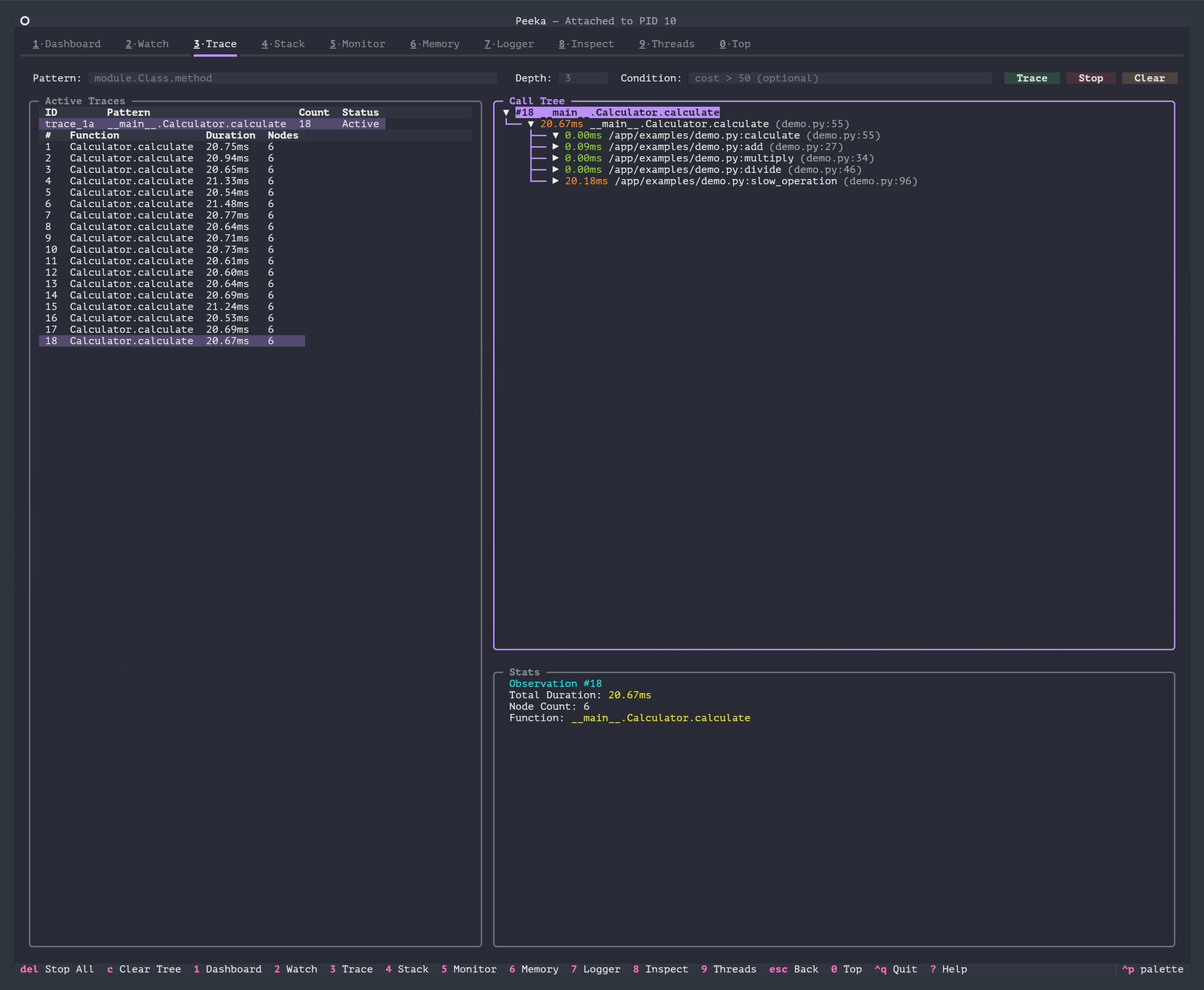
2. 視覚的な呼び出しツリー(TUI)
TUI モードでは、呼び出しツリーが可視化されたツリー構造で表示されます:
説明:
- 左側の Active Traces には現在のトレースタスクと各オブザベーションの実行時間が表示されます
- 右側の Call Tree には展開/折りたたみ可能な呼び出しツリーが表示されます
- 色分けによって実行時間の範囲が強調されます
- 下部の Stats には選択中のオブザベーションの総実行時間、ノード数、関数名が表示されます
3. トレース深度の調整
# 深度 1:直接の呼び出しだけをトレース
peeka-cli trace "service.process" -d 1
# 深度 5:5 層の呼び出しをトレース
peeka-cli trace "service.process" -d 5
深度比較の例:
# 元の呼び出しチェーン
process() → validate() → check_type() → isinstance()
├── query_db() → execute() → connect()
└── format_result() → json.dumps()
# depth=1
process() → validate()
→ query_db()
→ format_result()
# depth=2
process() → validate() → check_type()
→ query_db() → execute()
→ format_result() → json.dumps()
# depth=3(デフォルト)
process() → validate() → check_type() → isinstance()
→ query_db() → execute() → connect()
→ format_result() → json.dumps()
4. 条件フィルタリング
# 合計時間が 50ms を超える呼び出しだけをトレース
peeka-cli trace "api.handler" --condition "cost > 50"
# パラメータと時間の条件を組み合わせ
peeka-cli trace "service.query" --condition "cost > 100 and params[0] > 1000"
5. 組み込み関数のスキップ
# デフォルトの動作:組み込み関数をスキップ(出力のノイズを減らす)
peeka-cli trace "mymodule.func"
# すべての呼び出しを表示(組み込み関数も含む)
peeka-cli trace "mymodule.func" --skip-builtin=false
組み込み関数の例:
- Python 組み込み関数:
len(),str(),isinstance(),print() - 標準ライブラリ関数:
json.dumps(),os.path.join(),datetime.now()
実装技術
実装原理
Peeka の trace コマンドは、Python バージョンに応じて自動的に最適な実装方法を選択します:
| Python バージョン | 実装方案 | 性能オーバーヘッド | 説明 |
|---|---|---|---|
| 3.12+ | sys.monitoring | < 5% | 公式 PEP 669 API、最適な性能 |
| 3.8.1-3.11 | sys.settrace | < 20% | 互換性が良く、自動的に有効化 |
gevent 互換性(v0.1.15+):target プロセスで gevent monkey patch または active hub が検出された場合、trace は sys.settrace が frame stack 不変条件を壊すことを避けるため wrapper_only バックエンドに退化します。このモードでも target 関数の観測結果は報告されますが、再帰的な呼び出しツリーは提供されません。
sys.monitoring 実装 (Python 3.12+):
- PEP 669 に基づく公式モニタリング API
PY_STARTとPY_RETURNイベントを使用して呼び出しをキャプチャ- 性能オーバーヘッド < 5% で、本番環境での使用が推奨
- 複数の観測が自動的にツール ID を割り当てられ、競合しない
sys.settrace 実装 (Python 3.8.1-3.11):
- Python 組み込みの
sys.settrace()メカニズムを使用 - ターゲット関数の実行中にのみ有効(部分トレース)
- 性能オーバーヘッド < 20% で、ほとんどのシナリオで十分に利用可能
skip-builtin フィルタリングメカニズム:
code.co_filename.startswith('<')をチェックして組み込み関数(<built-in>)をフィルタリング- Python 標準ライブラリパスをチェックし、標準ライブラリ関数をフィルタリング
- デフォルトで有効、50% 以上の出力ノードを削減できる
性能への影響
性能オーバーヘッド
| シナリオ | オーバーヘッド | 説明 |
|---|---|---|
| 単純な関数 | < 5% | Python 3.12+ |
| 単純な関数 | < 20% | Python 3.8.1-3.11 |
| 複雑な呼び出しツリー(深度 5) | 10-30% | Python バージョンに応じて |
| 高頻度呼び出し(>1000 QPS) | 20-50% | 推奨されるのは観測回数の制限 |
説明:
- Python 3.12+ では
sys.monitoringを使用するため、性能オーバーヘッドが大幅に削減される - 深度が深いほど、性能オーバーヘッドは大きくなる
- 本番環境では条件フィルタリングと回数制限を使用することが推奨される
性能最適化の提案
- トレース深度を制限する
# 3 層までにトレースを制限 peeka-cli trace "func" -d 3 - 組み込み関数をスキップする
# デフォルトで有効、50% 以上のノードを削減 peeka-cli trace "func" --skip-builtin - 条件フィルタリングを使用する
# 遅い呼び出しだけをトレース peeka-cli trace "func" --condition "cost > 100" - 観測回数を制限する
# 10 回だけ観測 peeka-cli trace "func" -n 10 - 最小時間フィルタリング
# 10ms を超える呼び出しだけを記録 peeka-cli trace "func" --min-duration 10
使用例
1. 性能ボトルネックの特定
# 遅いインターフェースをトレースし、最も時間のかかるサブ呼び出しを見つける
peeka-cli trace "api.handler.process_request" --condition "cost > 100"
出力:
`---[1250ms] api.handler.process_request()
+---[10ms] api.validator.check_params()
+---[1200ms] database.query.execute() ← ボトルネックはここ!
| +---[50ms] database.connection.connect()
| `---[1150ms] database.cursor.fetch_all()
`---[20ms] api.formatter.to_json()
結論:データベースクエリが 96% の時間を消費しているので、SQL の最適化やインデックスの追加が必要です。
2. 再帰呼び出しの分析
# 再帰関数の実行深度と時間をトレース
peeka-cli trace "algorithm.factorial" -d 10
出力:
`---[5.2ms] algorithm.factorial(n=5)
`---[4.1ms] algorithm.factorial(n=4)
`---[3.0ms] algorithm.factorial(n=3)
`---[2.0ms] algorithm.factorial(n=2)
`---[1.0ms] algorithm.factorial(n=1)
`---[0.1ms] algorithm.factorial(n=0)
3. コード実行パスの理解
# 条件分岐の実行パスをトレース
peeka-cli trace "service.business_logic" -n 1
正常フローの場合:
`---[50ms] service.business_logic()
+---[5ms] service.validate_input()
+---[30ms] service.process_data()
`---[10ms] service.save_result()
異常フローの場合:
`---[20ms] service.business_logic()
+---[5ms] service.validate_input()
+---[10ms] service.handle_invalid_input()
`---[3ms] service.log_error()
4. 最適化前後の性能比較
# 最適化前
peeka-cli trace "converter.parse_json" -n 10 > before.jsonl
# 最適化後
peeka-cli trace "converter.parse_json" -n 10 > after.jsonl
# 平均実行時間を分析
jq '.total_duration_ms' before.jsonl | awk '{sum+=$1; count++} END {print "Before:", sum/count, "ms"}'
jq '.total_duration_ms' after.jsonl | awk '{sum+=$1; count++} END {print "After:", sum/count, "ms"}'
5. CI/CD への統合
#!/bin/bash
# 性能回帰テスト
THRESHOLD=100 # 最大許容時間 100ms
peeka-cli attach $PID
RESULT=$(peeka-cli trace "critical.function" -n 50 | \
jq -s 'map(select(.type == "observation")) | map(.total_duration_ms) | add / length')
if (( $(echo "$RESULT > $THRESHOLD" | bc -l) )); then
echo "Performance regression detected: ${RESULT}ms > ${THRESHOLD}ms"
exit 1
fi
データ処理と分析
jq を使用した処理
# 1. 呼び出しツリーを抽出
peeka-cli trace "func" | jq '.call_tree'
# 2. 平均実行時間を計算
peeka-cli trace "func" -n 100 | jq '.total_duration_ms' | \
awk '{sum+=$1; count++} END {print "avg:", sum/count, "ms"}'
# 3. 最も遅いサブ呼び出しを見つける
peeka-cli trace "func" | jq '.call_tree | .. | objects | select(.duration_ms != null) | {function, duration_ms}' | \
jq -s 'sort_by(.duration_ms) | reverse | .[0]'
# 4. 呼び出し頻度を統計
peeka-cli trace "func" -n 100 | jq '.call_tree | .. | objects | select(.function != null) | .function' | \
sort | uniq -c | sort -rn
# 5. フレームグラフ用データを生成
peeka-cli trace "func" -n 1000 | jq -r '.call_tree | .. | objects | select(.function != null) | "\(.function) \(.duration_ms)"' > flamegraph.txt
Python による分析
import json
import sys
from collections import defaultdict
# 各サブ呼び出しの合計時間と回数を統計
stats = defaultdict(lambda: {"count": 0, "total_ms": 0})
for line in sys.stdin:
data = json.loads(line)
if data["type"] == "observation":
def traverse(node):
if "function" in node:
stats[node["function"]]["count"] += 1
stats[node["function"]]["total_ms"] += node.get("duration_ms", 0)
for child in node.get("children", []):
traverse(child)
for root in data["call_tree"]:
traverse(root)
# 合計時間でソート
sorted_stats = sorted(stats.items(), key=lambda x: x[1]["total_ms"], reverse=True)
print("Top 10 Time-Consuming Functions:")
print(f"{'Function':<60} {'Count':>10} {'Total (ms)':>15} {'Avg (ms)':>12}")
print("-" * 100)
for func, stat in sorted_stats[:10]:
avg_ms = stat["total_ms"] / stat["count"]
print(f"{func:<60} {stat['count']:>10} {stat['total_ms']:>15.2f} {avg_ms:>12.2f}")
実行:
peeka-cli trace "module.func" -n 100 | python analyze_trace.py
出力:
Top 10 Time-Consuming Functions:
Function Count Total (ms) Avg (ms)
----------------------------------------------------------------------------------------------------
database.query.execute 100 12500.00 125.00
api.handler.process_request 100 15000.00 150.00
json.dumps 500 1000.00 2.00
...
よくある問題
1. トレース深度が足りない
問題:呼び出しツリーが 3 層しか表示されないが、実際にはもっと多くの階層がある。
解決策:
# 深度制限を増やす
peeka-cli trace "module.func" -d 10
# 注意:深度が大きいと性能オーバーヘッドが増加します
2. 出力データが多すぎる
問題:組み込み関数の呼び出しが大量に含まれ、出力が読みにくい。
解決策:
# 組み込み関数をスキップ(デフォルトで有効)
peeka-cli trace "module.func" --skip-builtin
# 10ms を超える呼び出しだけを記録
peeka-cli trace "module.func" --min-duration 10
# 条件フィルタリングを使用
peeka-cli trace "module.func" --condition "cost > 50"
3. 性能オーバーヘッドが大きすぎる
問題:trace を有効にするとアプリケーションの応答が遅くなる。
解決策:
# 1. トレース深度を減らす
peeka-cli trace "module.func" -d 2
# 2. 観測回数を制限する
peeka-cli trace "module.func" -n 10
# 3. 条件フィルタリングを使用し、遅い呼び出しだけをトレース
peeka-cli trace "module.func" --condition "cost > 100"
# 4. Python 3.12+ にアップグレードすると性能が向上します
4. データが観測できない
考えられる原因:
- 関数が呼び出されていない
- 関数名のスペルが間違っている
- 条件式が厳しすぎる
- 既に観測回数制限(-n パラメータ)に達している
調査手順:
# 1. 関数名が正しいか確認
python3 -c "import mymodule; print(mymodule.MyClass.my_method)"
# 2. 条件式を削除して、まず 1 回観測
peeka-cli trace "mymodule.func" -n 1
# 3. プロセスが存在するか確認
ps aux | grep <pid>
高度なテクニック
1. フレームグラフの生成
# トレースデータを収集
peeka-cli trace "module.func" -n 1000 > trace.jsonl
# フレームグラフ形式に変換
jq -r '.call_tree | .. | objects | select(.function != null) | "\(.function);\(.duration_ms)"' trace.jsonl \
> folded.txt
# フレームグラフを生成(flamegraph.pl が必要)
flamegraph.pl folded.txt > flamegraph.svg
2. 複数バージョンの性能比較
# バージョン A
git checkout v1.0
peeka-cli trace "module.func" -n 100 > trace_v1.jsonl
# バージョン B
git checkout v2.0
peeka-cli trace "module.func" -n 100 > trace_v2.jsonl
# 平均実行時間を比較
echo "v1.0: $(jq -s 'map(.total_duration_ms) | add / length' trace_v1.jsonl) ms"
echo "v2.0: $(jq -s 'map(.total_duration_ms) | add / length' trace_v2.jsonl) ms"
3. 自動化性能モニタリング
#!/usr/bin/env python3
"""性能回帰監視スクリプト"""
import json
import subprocess
import time
THRESHOLD = 100 # 最大許容時間 (ミリ秒)
CHECK_INTERVAL = 3600 # チェック間隔 (秒)
def check_performance(pid, pattern):
cmd = ["peeka-cli", "trace", pattern, "-n", "50"]
proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, text=True)
durations = []
for line in proc.stdout:
data = json.loads(line)
if data["type"] == "observation":
durations.append(data["total_duration_ms"])
avg_duration = sum(durations) / len(durations) if durations else 0
if avg_duration > THRESHOLD:
send_alert(f"Performance regression: {avg_duration:.2f}ms > {THRESHOLD}ms")
return avg_duration
def send_alert(message):
# アラートを送信(メール、Slack、钉钉など)
print(f"ALERT: {message}")
if __name__ == "__main__":
pid = int(sys.argv[1])
pattern = sys.argv[2]
while True:
duration = check_performance(pid, pattern)
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] Avg duration: {duration:.2f}ms")
time.sleep(CHECK_INTERVAL)
4. Prometheus への統合
from prometheus_client import Histogram, start_http_server
import json
import subprocess
# メトリクスを定義
trace_duration = Histogram('trace_duration_ms', 'Function trace duration', ['function'])
# Prometheus サーバーを起動
start_http_server(8000)
# トレースデータを収集
proc = subprocess.Popen(
["peeka-cli", "trace", "module.func"],
stdout=subprocess.PIPE,
text=True
)
for line in proc.stdout:
data = json.loads(line)
if data["type"] == "observation":
# 呼び出しツリーを再帰的に処理
def record_metrics(node):
if "function" in node and "duration_ms" in node:
trace_duration.labels(function=node["function"]).observe(node["duration_ms"])
for child in node.get("children", []):
record_metrics(child)
for root in data["call_tree"]:
record_metrics(root)
参考資料
更新履歴
| バージョン | 日付 | 更新内容 |
|---|---|---|
| 0.2.0 | 2026-02 | trace コマンドのドキュメントを追加 |
| 0.1.0 | 2025-01 | 初期バージョン |
更新履歴
| バージョン | リリース日 | 変更内容 |
|---|---|---|
| 0.1.17 | 2026-06-13 | trace レスポンスが wrapper_only バックエンドに降格された際、runtime_meta(startup_backend、effective_backend、downgrade_reason)を含むように。TUI の Trace ビューは統計パネルに Backend / Gevent 状態を表示 |
| 0.1.16 | 2026-06-07 | --client を追加 |
| 0.1.15 | 2026-05-27 | gevent patched/active hub ランタイムでは wrapper_only trace バックエンドに退化 |
| 0.1.12 | 2026-05-08 | TUI パネルシステムの統一、レスポンシブレイアウトの改善(commit 50c4af4) |
| 0.1.11 | 2026-05-07 | 安定ソースによるクライアントラベリング(commit 965ff22)、アクティビティ診断の強化(commit b1b0412) |
| 0.1.10 | 2026-05-04 | TUI ボタン色の正規化(commit fd6a0a1)、アクティビティログ折り返しの可読性向上(commit 5f46ae8) |